

連載コラム『データ分析』
第7回 データ分析実践編②(最終回)
2016.09.29
データ分析、第7回目です。今回が最終回となります。
前回に引き続き、実際に簡単なテーマを設定して分析を実践してみたいと思います。
データ分析の流れ(おさらい)
前回同様、この流れに沿って実際のテーマに取り組んでみましょう。
データ分析実践編
テーマ2:演説内容分析
前回とはガラッと変わって文章の分析を紹介します。
「テキストマイニング」という単語が注目されているように、文章や単語を分析して何かを発見したい、といったニーズも高まっています。
「総理大臣の演説内容から、総理がどのような演説を行い何に注目しているのかを調べたい」といったテーマを考えたいと思います。
演説でどのような単語が多く使われているかを分析してみましょう。
総理の演説内容は外務省のwebページにて公開されているため、そちらのデータを利用します。
今回は単語に着目したいのですが、日本語の文章は単語と単語の間に区切りがありません。
「すもももももももものうち」という文章があった場合、人間なら
 と理解できますが、コンピュータに区切り目はわかりません。
と理解できますが、コンピュータに区切り目はわかりません。
そこで、コンピュータに単語の辞書を与え、言葉ごとに分割できるようにする形態素解析という技術を用います。この技術により文章を分解して単語を抽出することができます。
単語単位に分割できたことで、どのような単語が多く使われているか集計することができます。ためしに頻出形容詞の集計を行ってみるとこのようになりました。
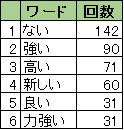
ポジティブな形容詞が多く出現しています。「新しい」や「力強い」が多く出現することから、熱のこもった演説である様子が想像できます。
頻出1位の「ない」も、「切れ目のない」、「遜色ない」や「~しなければならない」など、力強い文章に出てくるものでした。
テキストマイニングでよく利用される考え方として共起性の分析があります。これはどの単語とどの単語が同時に登場しているか、ということに着目した分析手法です。
例えば今回、「日本」という単語とセットでどんな単語が登場しているか、というようなことを調べることができます。
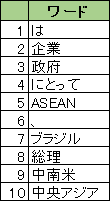
日本と“近い”単語はこのようになりました。
「は」や「、」はひとまず置いておくとして、地名や国名に特徴が見られます。
ASEANや中央アジア、中南米が話題に挙がっていることがわかります。
 共起は以前に連載で紹介したレコメンデーションにも使われる考え方です。
共起は以前に連載で紹介したレコメンデーションにも使われる考え方です。
これらの結果から仮説を導き出し、さらに分析を進めていくという流れです。
- ASEANや中南米との連携を重視している?
- 過去の総理大臣と比較すると頻出単語が異なるかもしれない。そこから総理大臣の特徴を現す単語がわかります。
また、集計結果や仮説の検証結果を活用することも考えられます。
例えば様々な議員の演説や発言を同様に分析し、単語の出現傾向から「発言の類似度を算出するモデル」ができたすると、総理大臣との主義主張の相違を明らかにしたり、類似の意見を持つグループを分類し、政策の検討や選挙の際の参考情報として活用したりすることができるかもしれません。
このようなテキスト分析は、企業での活用も急速に進んでいます。
例えば自社商品の評判を知るには、インターネット上に書かれる批評の記事、個人のつぶやき、SNS内での話題性などに着目するというようなことも多くの企業で行われていますし、SNSや個人のブログから流行の兆しを捕らえたり、顧客情報を収集したりすることでマーケティングに活用する例などがあります。
 データ分析は思いもよらない答えをもってくる魔法の箱ではありません。
データ分析は思いもよらない答えをもってくる魔法の箱ではありません。
